This is the main thing I created this plugin for. To create content for my sites on regular basis while using data from other sites as input.
In this setup I’m using a simple URL in list condition, which should be set to run on regular intervals using a cronjob (there’s plenty of cronjob manager plugins for wordpress which make this easy; I made go into more details about setting up a cronjob somewhere else or at a later date).
When the URL is visited (by the cronjob or by you in the browser) it will start doing the actions in order of appearance to create the content and post it to wordpress.
Import this file to get this exact setup
RSS and bing results for content creation.wpitl (5.2 KB)
A general overview:
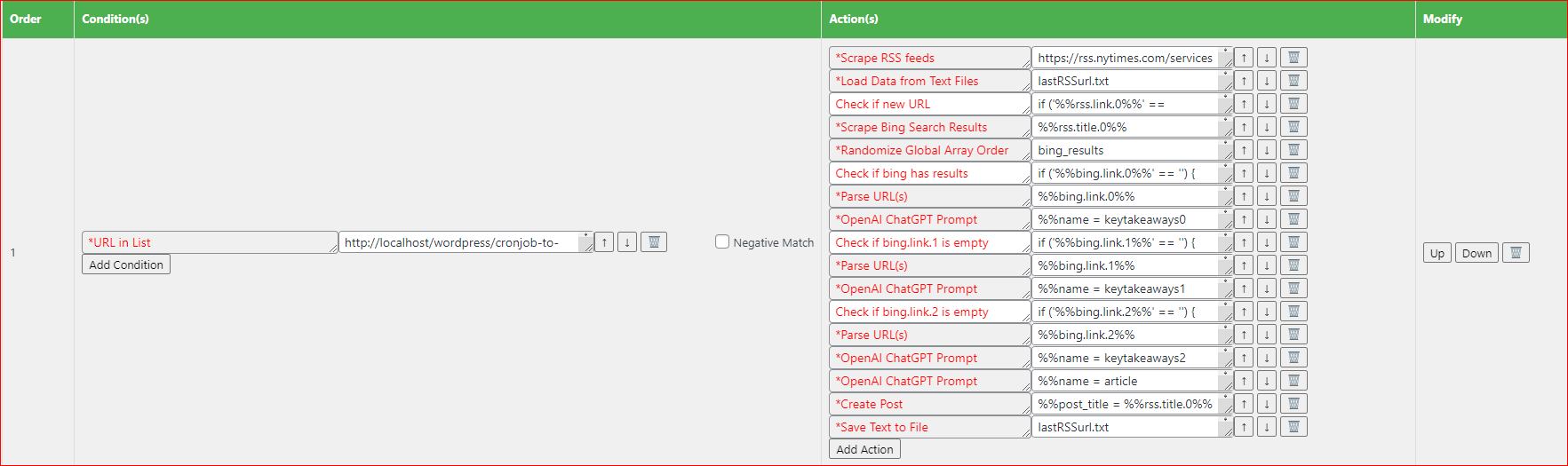
1st action: it scrapes an RSS feed. It pulls all links (aka URLs) and titles into an array.
https://rss.nytimes.com/services/xml/rss/nyt/US.xml
Any of these links and titles can be used in later actions by using the shortcodes
%%rss.link.0%% would get replaced by the first link from the RSS feed
%%rss.title.0%% would get replaced by the first title from the RSS feed
%%rss.link.1%% would get replaced by the second link from the RSS feed
%%rss.title.1%% would get replaced by the second title from the RSS feed
etc.
2nd action: it loads in data from a text file (also into an array)
lastRSSurl.txt
3rd action: it compares the latest link from the RSS feed to what was in the text file. If there are the same, that means this latest RSS link was already used to create content for and thus want to skip all remaining actions. Because otherwise we would be creating articles about the same topic multiple times.
if ('%%rss.link.0%%' == '%%lastRSSurl.link.0%%') {
itl_debug_log('There is no new post');
itl_debug_log('Action executed: ' . $action['name']);
$skipNextAction = 99;
}
4th action: here it does a query on the bing search engine using the title of the first rss feed item as keyword
%%rss.title.0%%
5th action: this randomizes the array with results from bing and trims it to only keep 3. This is done to be able to use the contents from 3 random results instead of simply using the top 3. If you wanted to use the top 3, you would not include this action.
bing_results
3
6th action: this checks if the query on bing returned results. if it didn’t we skip all remaining actions as we then can’t proceed properly. Unfortunately bing sometimes decides to not give us the data we want.
f ('%%bing.link.0%%' == '') {
itl_debug_log('bing.link.0 is empty');
itl_debug_log('Action executed: ' . $action['name']);
$skipNextAction = 99;
}
7th action: parses content of an the first link that is in the bing array (which was randomized, thus it’s not the top result). Which means it tries to grab all the content thats on the page and removes all the HTML tags and such.
%%bing.link.0%%
8th action: we ask chatGPT to create a key takeaway (bulletpoint) list of the content that we just parsed. We also name the output of chatGPT keytakeaways0 so that we can easily use the outputs in later actions.
note that we have several shortcodes in the prompt which automatically get replaced:
%%bing.title.0%% get replaced by the first title of the (randomized) results of the query done in bing
%%parsed.%%bing.link.0%%%% gets replaced by the parsed content from the first link/URL from the (randomized) results of the query done in bing
%%name = keytakeaways0
Please ignore all previous instructions. I want you to only answer in English. Summarize the next chunk of the web page into a list of key takeaways. Each key takeaway should be a bullet list item with an emoji. Here is a format:
- [emoji 1] [takeaway 1]
- [emoji 2] [takeaway 2]
Please try to use relevant but different emojis for each takeaway. Do not render brackets.
[WEB PAGE TITLE]:
%%bing.title.0%%
[WEB PAGE CHUNK]:
%%parsed.%%bing.link.0%%%%
[KEY TAKEAWAYS LIST]:
The next actions are essentially repeating the above 3 actions but with the 2nd and 3rd result from the bing query. Difference being that if a link is empty we don’t skip ALL remaining actions, but only the next 2, as those are relevant for that particular link/URL. Also note that we’re naming the output from the GPT prompt differently, so can differentiate them
9th action: Check if bing.link.1 is empty
if ('%%bing.link.1%%' == '') {
itl_debug_log('bing.link.1 is empty');
itl_debug_log('Action executed: ' . $action['name']);
$skipNextAction = 2;
}
10th action: Parse URL
%%bing.link.1%%
11th action: Prompt chatGPT
%%name = keytakeaways1
Please ignore all previous instructions. I want you to only answer in English. Summarize the next chunk of the web page into a list of key takeaways. Each key takeaway should be a bullet list item with an emoji. Here is a format:
- [emoji 1] [takeaway 1]
- [emoji 2] [takeaway 2]
Please try to use relevant but different emojis for each takeaway. Do not render brackets.
[WEB PAGE TITLE]:
%%bing.title.1%%
[WEB PAGE CHUNK]:
%%parsed.%%bing.link.1%%%%
[KEY TAKEAWAYS LIST]:
12th action: Check if bing.link.2 is empty
if (‘%%bing.link.2%%’ == ‘’) {
itl_debug_log(‘bing.link.2 is empty’);
itl_debug_log('Action executed: ’ . $action[‘name’]);
$skipNextAction = 2;
}
13th action: Parse URL
%%bing.link.2%%
14th action: Prompt chatGPT
%%name = keytakeaways2
Please ignore all previous instructions. I want you to only answer in English. Summarize the next chunk of the web page into a list of key takeaways. Each key takeaway should be a bullet list item with an emoji. Here is a format:
- [emoji 1] [takeaway 1]
- [emoji 2] [takeaway 2]
Please try to use relevant but different emojis for each takeaway. Do not render brackets.
[WEB PAGE TITLE]:
%%bing.title.2%%
[WEB PAGE CHUNK]:
%%parsed.%%bing.link.2%%%%
[KEY TAKEAWAYS LIST]:
15th action: Prompt chatGPT to mix the previous outputs together and write an article about it.
Note that we’re using the shortcodes %%gpt.keytakeaways0%%, %%gpt.keytakeaways1%% and %%gpt.keytakeaways2%% to automatically insert the outputs of earlier GPT prompts.
%%name = article
Combine these lists of key takeaways. Remove any duplicate info and group them by relevance. Each key takeaway should be a bullet list item with an emoji. Here is a format:
Key Takeaways:
- [emoji 1] [takeaway 1]
- [emoji 2] [takeaway 2]
Please try to use relevant but different emojis for each takeaway. Do not render brackets.
%%gpt.keytakeaways0%%
%%gpt.keytakeaways1%%
%%gpt.keytakeaways2%%
After combining the key takeaways. Write an article about and UNDERNEATH them. Don't mention 'article' nor 'key takeaways' and don't write a conclusion. Add h2 headings using markdown in the article
16th action: Create post. Here we tell it to create a post using the output from the previous action.
- We use the original title from the RSS feed as is in this example, but we could have just as easily asked GPT to rewrite it in some way.
- the post content uses the output from the previous GPT prompt and parses it down to HTML as GPT should’ve returned it using markdown which we can’t post to wordpress as is.
%%post_title = %%rss.title.0%%
%%post_content =
%%%parsedown.%%gpt.article%%%%%
We can also set status (default is draft), author, tags and category if we want to but that’s not done in this example.
17th action: Save text to File. Remember how we grabbed data from a text file in the 2nd action and then did a comparison in the 3rd action? We need to update that text file to make sure the next time this cronjob runs it won’t create new content about the same topic.
lastRSSurl.txt
key|link
0|%%rss.link.0%%
Example generated article using this exact setup:
